As everyone in cybersecurity knows, one of the biggest obstacles to identifying and remediating threats quickly is the sheer volume of data to sift through. Duplicate data is a common cause of wasted effort and, particularly in larger environments, this can cause significant time delays and critical setbacks to mitigation. Vulnerability and risk management data is no different, and at Vulcan Cyber® we are continually innovating to make sure that you’re spending your time focused on productive activities, like making sure you aren’t unnecessarily repeating your efforts.
This starts with deduplication in multiple ways. The first and most obvious step is to consolidate and deduplicate scan results so that when a unique vulnerability is identified by multiple scanners, you only see a single record with all relevant risk context. This is done automatically on the backend, and when the record is created it clearly communicates which different scanners identified the vulnerability.
But we also give you the ability to see and take bulk actions on logical, consolidated groupings of impacted software and identified CVEs that we call clusters. These cluster views allow you to better understand the real impact of your risk in context, to take a more data-driven approach to risk-prioritized vulnerability management, and to rapidly mitigate critical vulnerabilities and risk at scale. And that’s what I’d like to focus on here.
In my latest video, I talk about Vulcan Cyber’s Vulnerability Cluster feature, introducing a new way to look at vulnerabilities as related groups rather than as specific flaws attached to specific assets. It’s a different take on the usual “group by CVE” or “group by asset” approach.
If you haven’t seen the video yet, I’ll explain what we’re talking about with Vulnerability Clusters. You can watch the full recording here.
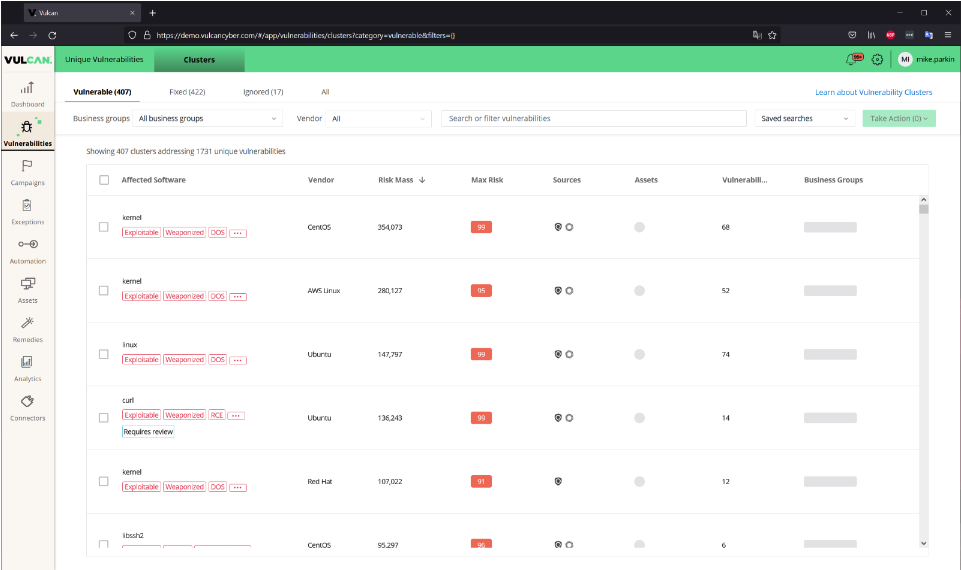
Rather than looking at specific vulnerabilities, usually by CVE as mentioned, this is a way to look at the common threads that tie multiple vulnerabilities together. Since the reality is that there are often multiple separate vulnerabilities, with separate CVE numbers and CVSS scores, that can be correlated and combined into a single fix, this is a sensible way to look at it.
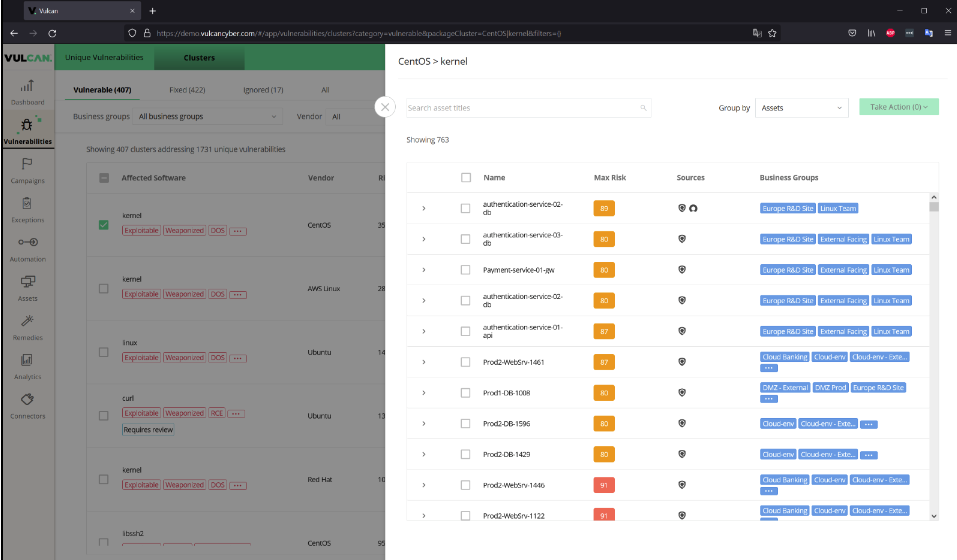
The example here looks at all the “Kernel vulnerabilities under CentOS” of which there are actually quite a few. In this case from our demo instance, it’s 68 separate vulnerabilities affecting 763 different assets. By any account, that’s a lot. And this is only counting the vulnerabilities that are reported within our environment. But this way of clustering them together makes it easier to deal with as a whole. Using Vulcan Cyber’s built-in actions, it’s possible to create trouble tickets or deploy solutions that can track and correct all of the related vulnerabilities en masse.
So, rather than looking at individual CVEs and correcting them one at a time, and finding out after deploying the first kernel upgrade, or patch, or whatever, that you’ve covered multiple CVEs (a good thing™ to be sure) you can understand that going in. By grouping the vulnerabilities into clusters like this, you can see ahead of time how one patch can reduce your risk mass substantially and improve your security posture at the same time.
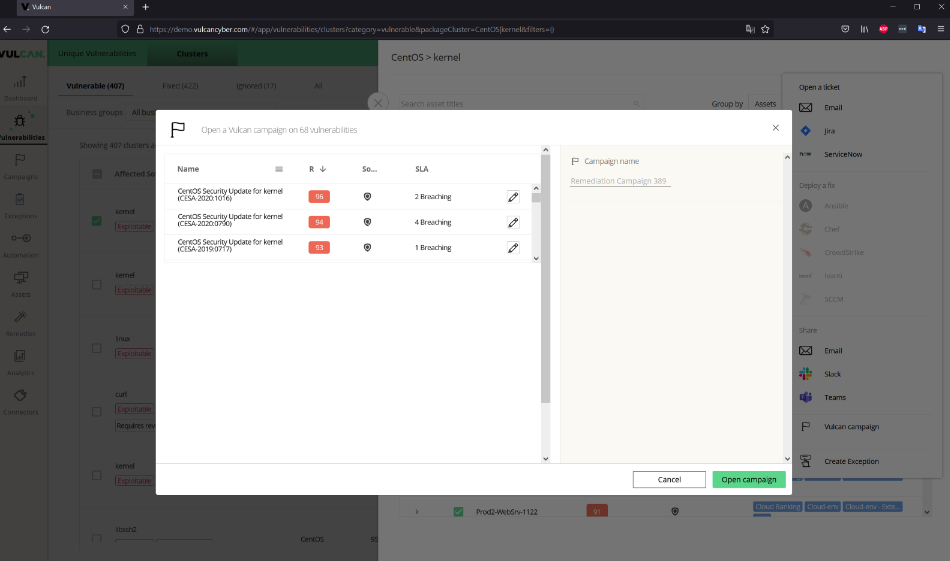
The ultimate goal here is to better manage cybersecurity risk to the organization, and it can be time consuming and inefficient to try and compile this information manually. While practitioners on the Security Operations and IT teams will generally see the world from the perspective of individual patches and specific vulnerabilities, the advantage comes at a higher level.
People who are looking at overall risk gain useful perspective here. As do people who are concerned with compliance. In both cases, they’re looking at a broader picture. Where a practitioner is often focused on remediating a specific problem, folks involved in risk management are concerned with whole areas of infrastructure.
Case in point. A Director in cybersecurity concerned with, say, a recent series of exploits against Kubernetes or Apache, for example, could look at the clusters associated with those applications rather than look up specific CVEs. They could use the knowledge to direct their teams to correct all of the affected assets, regardless of which specific CVE was involved.
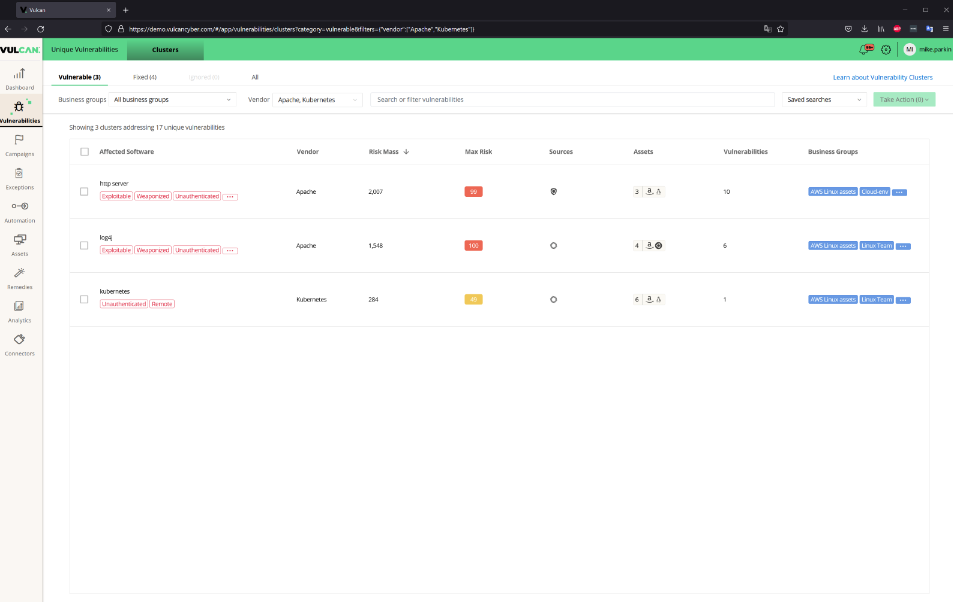
That’s just one case where clustering the vulnerabilities adds value to the security stack and lets both the Security Operations and Information Technology teams make better use of their time. There are other places where this is useful of course, and we’ll detail more specific use cases in the future.
But here, in a nutshell, is the Vulnerability Clusters feature in Vulcan Cyber. If you want to check it out for yourself, you can get your own instance of Vulcan Free and see how it works in your own environment.